(nie)szybki sposób na szybkie i wydajne wpisywanie bitów do pliku/pamięci.
Szybkie i wydajne wpisywanie bitów do pamięci w C
Cześć, to mój drugi wpis na wykopie, więc proszę mirki (bo chyba tak się tutaj zwraca) o wyrozumiałość :)
Ostatnio usiadłem sobie trochę do kochanego, dobrego C w celu zrobienia prostego formatu do grafiki dla prostego silnika działającego w oparciu o OpenGL. Pomyślałem, że jest to idealny moment aby przypomnieć sobie kodowanie Huffmana. Skoro kodowanie Huffmana to pojawia się problem wpisywania kodów symboli do pliku, czyli najpierw do pamięci.
Proste rozwiązanie
Najprostszym rozwiązaniem byłoby przesuwanie bitowe z maską, następnie bitowe zsumowanie z przesunięciem, jednak jest to tak samo niewydajne rozwiązanie jak kopiowanie sporych skupisk danych bajt po bajcie. Ja chciałem użyć czegoś w rodzaju memcpy, tylko że bitowego. Jeśli nie wiecie, to memcpy nie kopiuje bajt po bajcie, a słowo po słowie, albo nawet dwusłowo po dwuslowie. Słowo maszynowe można przyjąć że są to 2 bajty, oczywiście to zależy od architektury ale na tym się nie znam więc nic nie mowie. Podsumowując - chciałem kopiować więcej niż 1 bit za jednym zamachem.
Moje rozwiązanie
Ostatnim razem problem rozwiązałem nieco inaczej, ale teraz skupiłem się przede wszystkim na prostocie i szybkości. Na pewno da się to zrobić jeszcze lepiej, ale myślę, że moje rozwiązanie to i tak spory over kill.
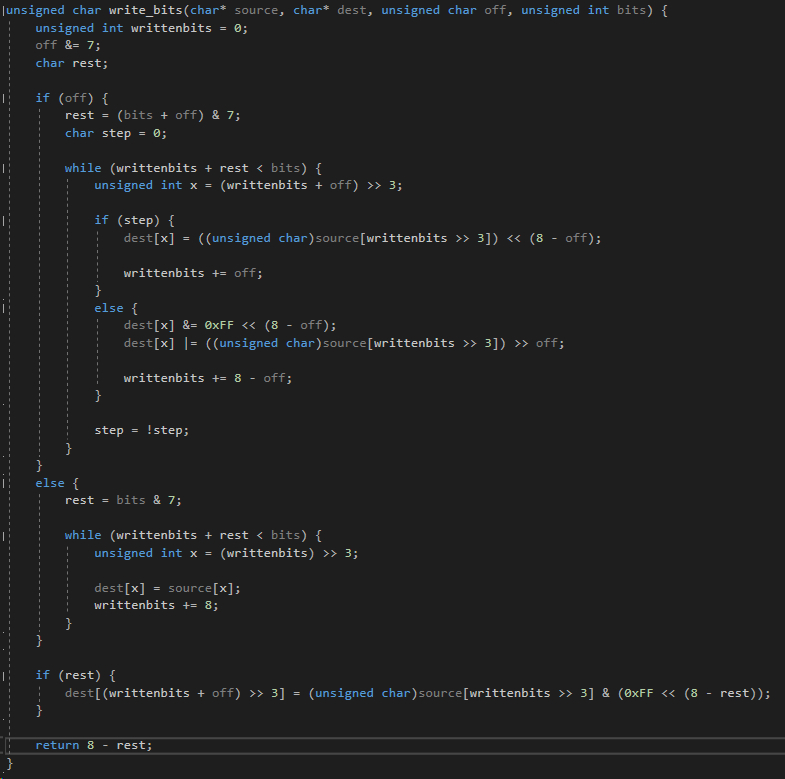
Zacznijmy od początku. Mamy funkcję write_bits. Zwraca ona "resztę" bitów - wpisując do pamięci 9 bitów wypełnimy 1 bajt i 1 bit, zatem następnym razem musimy zacząć wpisywać od 1 bajta i 2 bitu. Ten 1 bit to właśnie reszta, przesunięcie, offset.
Funkcja ta przyjmuje również kilka wartości - wskaźnik do danych wejściowych - to stąd kopiujemy, wskaźnik do danych wyjściowych - tutaj wklejamy, przesunięcie (off, offset), to właśnie to o czym przed chwilą mówilem, jeśli ostatnio wpisaliśmy 9 bitów to zapełniliśmy 1 bajt i 1 bit musielismy wpisać już do kolejnego bajtu, a więc nie możemy zacząć od początku drugiego bajta nadpisując ten 1 bit, musimy zacząć od 2 bitu. Bits to po prostu liczba bitów, które chcemy wpisać.
Writtenbits chyba nie muszę wyjaśniać - ilość bitów, którą już wpisaliśmy do przeznaczonej pamięci.
Dalej mamy "off &= 7", czyli skrócona wersja "off = off & 7". Ten iloczyn bitowy (jest w ogóle takie coś? chodzi o bitwise and) działa dokładnie tak samo jak %8, modulo 8. Offset nie może być większy niż 7, ponieważ wtedy po prostu przesuwamy bajt i dotyczy to wskaźnika.
Niżej znajduje się instrukcja warunkowa, która rozdziela problem na dwa podproblemy. Pierwsza sytuacja to taka, w której to startowe przesunięcie nie jest równe 0. Tutaj trzeba trochę pokombinować. Sprawę rozwiązałem poprzez podzielenie tego na jeszcze dwie sytuacje - kroki.
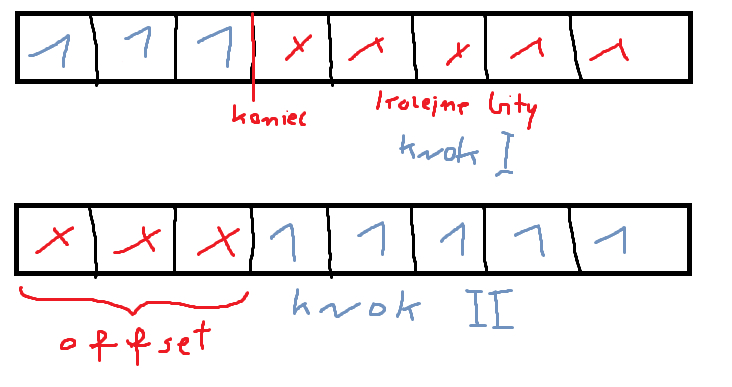
W pierwszym kroku wpisujemy na koniec bajtu, w drugim - na początek. Zaczynamy od kroku drugiego, czyli wpisywania na koniec bajtu, no bo pierwsze kilka bitów to offset, tutaj nie możemy pisać. Najpierw czyścimy ten obszar za pomocą bitowego ANDa, a potem bitowym ORem wpisujemy przesunięte dane, zwiększamy zmienną writtenbits o tyle, ile bitów wpisaliśmy (pełny bajt - offset, czyli 8 - offset) i odwracamy zmienną step, jeśli była prawdą, to teraz jest fałszem, w następnej iteracji przechodzimy do kroku pierwszego. Krok pierwszy jest łatwiejszy, nie musimy delikatnie czyścić bajtu, po prostu nadpisujemy go, ponieważ jest świeży.
Jeśli offset jest równy 0 to nie musimy nic przesuwać i po prostu kopiujemy całe bajty. Niektórzy może zapytają czemu nie użyłem memcpy tylko kopiowałem bajt po bajcie? Memcpy jest dobre do kopiowania np plików albo jakichś dużych danych, jednak do małych się nie nadaje. To tak jakby moją funkcją wpisywać po jednym bicie. Te dwa sposoby są dobre i mają przewagę tylko wtedy, gdy zapisujemy sporo danych, jeśli chcemy wpisywać bit po bicie, to nie warto męczyć się moim sposobem, jeśli chcemy wpisywać bajt po bajcie, nie warto używać memcpy. Na koniec jeszcze wystarczy wkleić końcówkę. Tutaj bez przesuwania, ponieważ w danych docelowych zaczynamy od świeżego bajtu, a w danych wejściowych nie ma przesunięcia. Wystarczy zamaskowanie niepotrzebnych bitów i voila, gotowe.
Mam nadzieję, że coś z tego zrozumieliście. Proszę o krytykę mojego pomysłu. Jestem amatorem, programowanie to po prostu moja zajawka i nie chcę trzymać swoich sposobów dla siebie, chce się nimi dzielić, bo może komuś pomogę. Dzięki za przeczytanie i zapraszam do dyskusji.