Aktywne Wpisy
fatoom87 +1532
Tez macie tak, że z wiekiem co raz mniej ciągnie was do alkoholu?
Jak pomyślę, że następnego dnia będę się czuł fatalnie to wolę nie pić, żeby ranio wskoczyć na rower czy porobic coś fajnego.
#alkoholizm #alkohol
Jak pomyślę, że następnego dnia będę się czuł fatalnie to wolę nie pić, żeby ranio wskoczyć na rower czy porobic coś fajnego.
#alkoholizm #alkohol

Beszczebelny +341
Obczajam ten kalkulator "kredytu 0%" i się śmieję xD
1. Single praktycznie wykluczeni czyli jako 30letni facet zarabiajacy np 8000zł nie masz szans na mieszkanie w mieście i tym samym jesteś wykluczony z przyszłego tworzenia związku, rodziny i produkcji ilości Polaków.
2. Patola z trójką dzieci może za to wziąć piękne deweloperskie mieszkanie za prawie 700 tys i płacić ratę....1375zł.
1375zł! xddd przecież przy tego typu racie to jest ogromne pole do
1. Single praktycznie wykluczeni czyli jako 30letni facet zarabiajacy np 8000zł nie masz szans na mieszkanie w mieście i tym samym jesteś wykluczony z przyszłego tworzenia związku, rodziny i produkcji ilości Polaków.
2. Patola z trójką dzieci może za to wziąć piękne deweloperskie mieszkanie za prawie 700 tys i płacić ratę....1375zł.
1375zł! xddd przecież przy tego typu racie to jest ogromne pole do
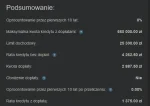
źródło: Screenshot 2024-04-12 at 08-03-44 Kalkulator Mieszkanie na Start_ Kredyt 0% – Hipoteka bez tajemnic
Pobierz{kind=link}
Aktywne Znaleziska





#programowanie #webdev #javascript #reactjs
@5z7k9: Zgadza się, appka w Angularze śmiga w Google aż miło. Tylko trzeba trochę rich data dodać, żeby to miało ręce i nogi
@Marmite: @informatyk15000k: no właśnie, dążenie do SEO komplikuje cały webdev... :P
@5z7k9: Dokładnie tak. Google serwujemy normalną stronę, resztę (Facebook, Slack itp.) zwyczajnie przekierowujemy na PhantomJS
= potrzebuję rozwiązania bez Node'a