Aktywne Wpisy
dzikiwonsz21 +8
Ale kupiłem gruza, ja #!$%@? XD
Ogólnie to aż się zastanawiam czy tego po prostu nie sprzedać na części czy do jakiegoś komisu, bo mechanik mi pewnie sporo krzyknie.
Kupiłem alfę 166, 2.4 jtd 136km a niżej lista "drobnostek" których Janusz sprzedaży mi nie opowiedział. Jak gadałem z nim przez telefon to mówił że jedynie tylnie zawieszenie i radio do zrobienia, a reszta jest super XD
Ogólnie to mam nadzieję, że za
Ogólnie to aż się zastanawiam czy tego po prostu nie sprzedać na części czy do jakiegoś komisu, bo mechanik mi pewnie sporo krzyknie.
Kupiłem alfę 166, 2.4 jtd 136km a niżej lista "drobnostek" których Janusz sprzedaży mi nie opowiedział. Jak gadałem z nim przez telefon to mówił że jedynie tylnie zawieszenie i radio do zrobienia, a reszta jest super XD
Ogólnie to mam nadzieję, że za

Wo0cash +180
#!$%@?, #!$%@?ć ten świat.
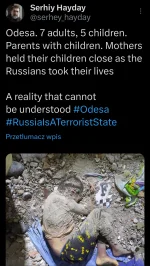
Ten chłopiec powinien jak każde dziecko żyć, rozwijać się, bawić się ze swoimi kolegami....
Ale nie będzie miał tej możliwości, bo chore "ambicje", czy zapędy imperialistyczne starego dziada muszą być spełnione, a życie ludzi to sprawa bez znaczenia.
I mało tego, są ludzie którzy mu w tym wtórują, ślepo wierząc w idę....sam nie wiem czego
Dziwny jest ten świat (╯︵╰,)
#wojna #ukraina #swiat
Ten chłopiec powinien jak każde dziecko żyć, rozwijać się, bawić się ze swoimi kolegami....
Ale nie będzie miał tej możliwości, bo chore "ambicje", czy zapędy imperialistyczne starego dziada muszą być spełnione, a życie ludzi to sprawa bez znaczenia.
I mało tego, są ludzie którzy mu w tym wtórują, ślepo wierząc w idę....sam nie wiem czego
Dziwny jest ten świat (╯︵╰,)
#wojna #ukraina #swiat
źródło: temp_file7337849322692185902
Pobierz{kind=link}
Aktywne Znaleziska





#programowanie #programista15k #naukaprogramowania #bigdata #sztucznainteligencja #deeplearning #python
Komentarz usunięty przez autora
Komentarz usunięty przez autora