
Jak wyciagnąć link ze strony po kliknięciu w pewien przycisk który wyswietla zmienioną listę na tej stronie? Link caly czas jest ten sam do konsoli a zmiana dziala jakoś z poziomu javascriptu... To jakbyś wszedł na pogodę na wp.pl i zamiast wp.pl/pogoda masz caly czas wp.pl #scrapping #python #javascript #html #webdev #php #webscraping

@fifiak: Rozpoczynasz przygodę ze grzebaniem od front-endu, poczytaj o Selenium albo playwright, frameworki które mogą 'udawać, że są zwykłym użytkownikiem (głównie stosowane do testów).
W ten sposób łatwo podjąć interakcję ze skryptami i dostać się do interesujących nas danych.
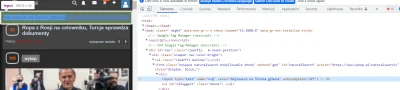
PS. Często otwierając konsolę deweloperską możemy znaleźć adresy URL do niepublicznych API które strona wykorzystuje do pobierania danych - jeśli nie masz zamiaru robić nic 'złego' to można w ten sposób dostać
W ten sposób łatwo podjąć interakcję ze skryptami i dostać się do interesujących nas danych.
PS. Często otwierając konsolę deweloperską możemy znaleźć adresy URL do niepublicznych API które strona wykorzystuje do pobierania danych - jeśli nie masz zamiaru robić nic 'złego' to można w ten sposób dostać
@fifiak a przykladowo jak w operze przez nagranie sesji i klikania mam jsob albo jakiś puppeteer to da rade łatwo to odpalić pythonem albo z poziomu basha? Bo nie wiem jak teraz wykorzystac ten kod a sa tam xpathy, clicki itp






















{kind=link}
{kind=link}
{kind=link}
Do logowania i poruszania się po stronie używam Mechanize. Wyczytałem, że Mechanize automatycznie przechowuje ciasteczka. Apkę mam napisaną obiektowo i rzeczywiście w każdej klasie oddzielnie inicjowałem mechanize.browser() logując się ponownie. Wymyśliłem, że zaloguję się raz, a potem będę starał się
1. Wg mojego ograniczonego doświadczenia prawidłowe (tzn sam bym zrobił tak samo/podobnie używając selenium), chociaż metoda login będzie próbowała zwrócić browser nawet jak będziesz miał błąd logowania i tutaj sie wywali całość.
Zastanowił bym się nad dodatkową klasa Browser gdzie ogarniesz logowanie, sprawdzanie czy dalej jesteś zalogowany czy nie, ewentualne ponowne logowanie w razie konieczności itp.
2. Puść skrypt na kilka godzin i zobacz czy sie wykrzaczy bez ponownego logowania