Aktywne Wpisy

rales +326
tag do obserwowania --> #sredniasondazysejm
WRZESIEŃ 2023
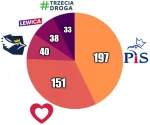
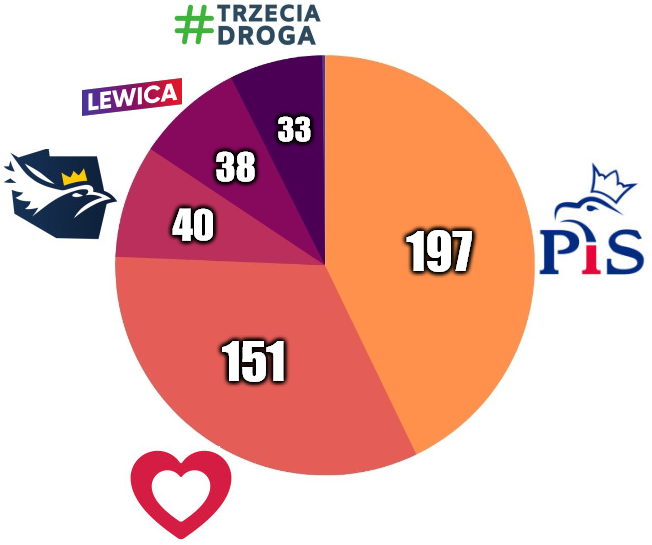
1. Prawo i Sprawiedliwość - 35,8% - 197 mandatów (⬆ 0,8%)
2. Koalicja Obywatelska - 28,4% - 151 mandatów (⬇ 1%)
3. Konfederacja - 9,7% - 40 mandatów (⬇ 0,5%)
4. Trzecia Droga - 9% - 33 mandaty (⬇ 0,5%)
5. Lewica - 8,7% - 38 mandatów (⬆ 0,5%)
WRZESIEŃ 2023
1. Prawo i Sprawiedliwość - 35,8% - 197 mandatów (⬆ 0,8%)
2. Koalicja Obywatelska - 28,4% - 151 mandatów (⬇ 1%)
3. Konfederacja - 9,7% - 40 mandatów (⬇ 0,5%)
4. Trzecia Droga - 9% - 33 mandaty (⬇ 0,5%)
5. Lewica - 8,7% - 38 mandatów (⬆ 0,5%)
Na które ugrupowanie zagłosujesz?
- Prawo i Sprawiedliwość 5.2% (191)
- Koalicja Obywatelska 48.4% (1773)
- Konfederacja 16.3% (598)
- Trzecia Droga 17.1% (626)
- Lewica 4.2% (155)
- Jeszcze nie wiem 6.2% (227)
- Nie idę na wybory 2.5% (91)

larine +120
Ostatnie afery związane z #polskiyoutube, zwłaszcza ta najobrzydliwsza dot. przestępstw, jakich dopuszczał się #stuu (choć z tego co mówił #wardega wynika, że razem z nim byli też inni youtuberzy), pokazują, że poziom większości użytkowników tego portalu to dno. Najbardziej plusowane komentarze skupiają się na obwinianiu 13-letnich dzieci o to, że poszły spotkać się ze swoim idolem. Jak można nie widzieć w tym nic złego, że dorosły mężczyzna wykorzystuje swoją pozycję do




{kind=link}
#sysadmin #devops
@szczeppan: Kopiowanie plików na których pracuje jakaś aplikacja rsynciem to proszenie się o kłopoty.
@maniac777: O ile się orientuję to polecenia blokuje replikację na slave, osobiście wybrałbym pg_dump który jest ogólnie wolniejszy ale nie blokuje nic i nie trzeba mieć replikacji. Ewentualnie snapshot całego dysku na systemie który to obsługuje, EBS ma np. taką możliwość.
@plushy: snapshoty mogę robić na ESXi ale nie chroni mnie to przed utrata sprzętu a przewalanie tych obrazów w tej chwili odpada (miedzy serwerami 100Mb)
Interesuje mnie natomiast czy można startbackup używać bez przerzucanie serwera w tryb read only czy jednak nie, bo jeśli baza ma być normalnie dostępna to pgdump jest lepszym rozwiązaniem nawet jeśli zależy nam nad tym by nie było przerw
@breja: To replikacja streaming.
https://wiki.postgresql.org/wiki/Streaming_Replication
Baza slave będzie dostępna do odczytu, ale pod pewnymi warunkami (jak w ramach replikacji przyjdzie log modyfikujący blok potrzebny do przeprowadzenia zapytania, to zapytanie zostanie przerwane). Jak Replikacja się wyrabia to po awarii sprzętu stracisz kilka do kilkunastu sekund. Failover jest operacją jednokierunkową i po jego przeprowadzeniu musisz zestawić replikację w drugą stronę.
@plushy @szczeppan: to chyba tak nie zadziala. Baza przy zamykaniu prawdopodobnie zostanie podciagnieta do stanu spojnego.