Aktywne Wpisy

Knamga +411
Czy nasz gatunek przetrwa?? #spermiarzalert #bekazpodludzi

ziuaxa +246
Zazwyczaj wrocławska policja swoją niekompetencją, opieszałością, agresją albo ignorancją i kretynizmem po prostu niszczy życie uczciwym obywatelom. Tym razem stało się inaczej i przez brak mózgu wyszło jak wyszło.
Typ od prawie roku był poszukiwany listem gończym, a na stałe przebywał w miejscu zameldowania. XD XD
XD
Typ od prawie roku był poszukiwany listem gończym, a na stałe przebywał w miejscu zameldowania. XD XD
"Transportujący go policjanci — Daniel Ł. i Łukasz K. to niezwykle doświadczeni funkcjonariusze. Pierwszy w służbie jest od ćwierć wieku, drugi od 19 lat"
XD
Piątkowa





{kind=link}
{kind=link}
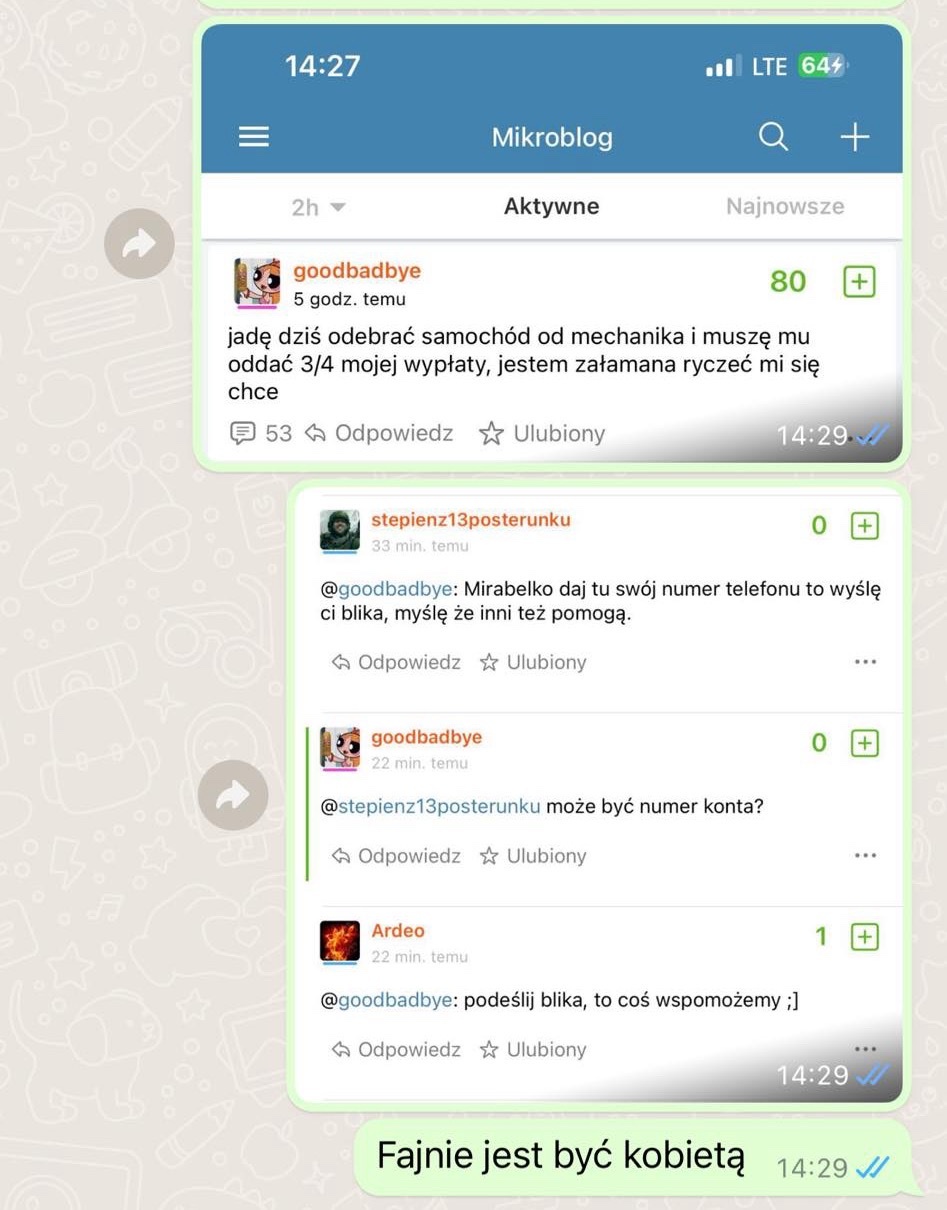
@luukasek: o to spoko opcja na pewno sie przyda
@Nemeczekes: tez piewsze slysze musze obczaic najpierw co to jest za bajer
Masz dużo plików o małym rozmiarze czy mało plików o dużym rozmiarze?
@rosso_corsa:
masz tu przyklad:
import glob
allPDF = []
def pliki():
for file in glob.glob("*dd*.csv"):
allPDF.append(file)
pliki()
kazdy plik csv co ma w nazwie dd i jest csv zostanie dodany do listy allPDF. mozesz sobie dowolnie modyfikowac
from glob import glob
listaPlikow = glob('D:\bdrozpakowana\*.csv')
print(listaPlikow)
Co wy robicie (⇀‸↼‶)
dataframes = [pd.read_csv(f) for f in listaPlikow]