Seria prezentacji na temat działania nowej architektury procesorów - nazywanej przez twórców "Mill".
Topowe procesory klasy Mill mają cechować się niezwykłą wydajnością na wat przy niskich kosztach wytworzenia chipu. Ma to być osiągnięte dzięki pozbyciu się ciężaru zgodności wstecznej i kilku fajnym trikom. Na stronie projektu:
//millcomputing.com/ można zapoznać się bliżej z architekturą a nawet poszczególnymi instrukcjami - te mają swoje strony wiki.
W części pierwszej Gandalf opisuje w jaki sposób procesory Mill potrafią wykonać 33 różne operacje w ciągu jednego cyklu zegara.
Część druga przedstawia sposób zapewnienia tym 33 operacjom w ciągu cyklu danych i odebranie od tych wszystkich operacji wyników.
Zrezygnowano z rejestrów, których nie da się mnożyć w nieskończoność na rzecz kolejki FIFO o swobodnym dostępie, nazywanej przez twórców "Belt"
Tematem trzeciego wykładu jest pamięć. Mill nie wykonuje programów poza kolejnością - jest to bardzo skomplikowane i energochłonne. Zamiast tego kompilator planuje program w odpowiedni sposób aby zmaksymalizować wydajność. Prezentacja opisuje metody radzenia sobie z cache-miss, zapewnieniem ochrony oraz tłumaczeniem adresów wirtualnych na fizyczne.
Czwarta część traktuje o przewidywaniu skoków warunkowych. Skoki warunkowe w programach zdarzają się bardzo często i nawet nie trafienie 5% oznacza duże straty wydajności. Współczesne algorytmy przewidywania skoków są dość skuteczne, jednak zawodzą gdy mają do czynienia ze 'świeżym', nie wykonywanym kawałkiem kodu.
Kolejny wykład opisuje metadane - dane o danych. Mill nie posiada rejestrów, więc nie da się powiedzieć "te 32 bity to liczba zmiennoprzecinkowa, bo siedzi w rejestrze zmiennoprzecinkowym". Dodatkowo metadane pozwalają na wykonywanie spekulatywne - wykonywanie obliczeń, bez naruszania ochrony pamięci, nawet gdy podąża się błędną ścieżką skoku warunkowego.
Tutaj też mamy chyba pierwszy przykład z życia, jak Mill może zaoszczędzić czas i energię na kopiowaniu ciągu znaków.
W szóstej prezentacji przybliżone są jednostki wykonawcze procesora - to co faktycznie dodaje i mnoży. Kolejny sposób zaoszczędzenia czasu poprzez "fazy". Dzięki temu, czas przeznaczony na zapis (wyplucie danych z alu) w instrukcjach, które nic nie produkują nie marnuje się. Podobnie z pobieraniem danych przez instrukcje, które nic nie pobierają.
Wykład nr 7 jest na temat zabezpieczeń - ochrona pamięci, prawa zapisu itd. Zalecam zapoznać się z wykładem 2.
Mill jest architekturą sprzyjającą mikro-jądrom. Zabezpieczenia stosowane tutaj są obowiązkowe i niekosztowne w zasoby i cykle procesora.
Kolejna prezentacja opisuje jak będzie wyglądać rodzina procesorów Mill. Jakie będą różnice i jak kompilator radzi sobie z nimi. Brak zgodności binarnej pomiędzy poszczególnymi członkami architektury może być większym problemem w niektórych dziedzinach (zamknięte sterowniki), a niektórych wręcz zaletą (małe programy do rozwiązań wbudowanych mogą być jeszcze bardziej kompaktowe).
Podczas prezentacji speaker wraz ze słuchaczami 'tworzą' nowy rodzaj procesora Mill (nie jest to bardzo widowiskowe tak naprawdę, ale fajnie że mają to tak zautomatyzowane)
Ostatnia obecnie dostępna prezentacja opisuje programową potokowość - dzięki metadanym i dużej ilości jednostek wykonawczych można znacząco przyspieszyć wykonywanie pętli. Ivan (tak ma naprawdę na imię ten Gandalf) przybliża też praktyczne działanie "pasa" (belt)
2 dni temu została wygłoszona jeszcze jedna prezentacja - o kompilatorach i innych narzędziach do tworzenia programów.
prawdopodobnie pojawi się na stronie
//millcomputing.com/docs/toolchain/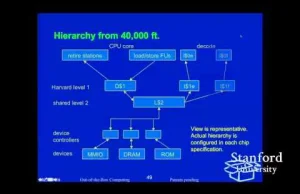







Komentarze (273)
najlepsze
Takie prezentacje przybliżą też ogólne zasady działania procesora - jak wygląda ochrona pamięci, przetwarzanie danych, na czym polega potokowość i czym różni się Pentium Pro od Haswella.
Na rynku desktopowym, workstation oraz serwer w latach 80 i 90 było dostępnych wiele różnych procesorów RISC (MIPS, SPARC, PowerPC, PA-Risc itd.) nawet CISC Motorolla z serii 6800xx miała lepszą architekturę niż Intel. Ale wszystkie zostały po prostu wymiecione przez x86. Nawet x86 pogrzebał swojego brata VLIW - Intel Itanium. Co z tego, że te wszystkie procesory były szybsze i zajmowały mniej miejsca na chipie skoro przez dużo mniejszą skalę
Jak pokażą prototyp który działa, to będzie ciekawie (tylko żeby się nie powtórzyło jak z Itanium albo Transmetą).
@AgresywnyKaloryfer: no nie wiem czy przypomina - Tutaj goście od 2 lat regularnie publikują slajdy i specyfikacje ich przyszłej maszyny. Jak tylko coś opatentują to opisują dokładnie na wiki, slajdach czy na forum. Tamci wypuści demo statycznej sceny nie tłumacząc za bardzo jak to ma działać od środka.
Nawet jak nic im nie wyjdzie z całego Milla, to niektóre pomysły wydają się rozsądne - może ktoś je zaadoptuje do czegoś
Kompilujesz go do czego?
@dr__slim: Czy chodziło ci o: big i little endian?
@siara-krakow: Z tego co zrozumiałem z przedostatniego filmiku assembler w tej architekturze jest oparty o C++ i każda instrukcja jest wywołaniem odpowiedniej funkcji.
Dajemy to jako drugi procesor, któremu będzie można zlecić pojedyncze podprogramy (funkcje i takie tam), na początek "poszukaj mi liczby pierwszej", potem coś większego "połknij obraz DVD, wypluj DivX" (czy co tam teraz w modzie), "weź mi sprawdź czy jak ludek A jest tutaj i wygląda tak, a ludek B jest tam i wygląda inaczej, to ludek A schowa się
A znasz jakiegoś użytkownika domowego?
Są tacy, którzy się rzucają kiedy im się skórkę na przeglądarce zmieni. Jak się taki czegoś nauczy, to go trzeba potem ręcznie przestawiać, bo jak coś jest "takie samo tylko że inne" to już się pojawia ściana nie do przeskoczenia.
A tak poza tym to mobilnym daleko do komputerów. Kurnik nie pójdzie, gra nie pójdzie (są, ale wiadomo jakie). Film obejrzysz, ale na komórce to
Myślisz, że to takie hop-siup wymienić wszystko? Popatrz z punktu widzenia użytkownika - na 5 letnim kompie wszystko działa oprócz nowych gier, to po cholerę zmieniać kompa? Co dadzą nowe technologie dla szaraka? Nic. Czy szybciej napisze dokument w wordzie czy wyliczy coś w Excelu? Nie.