
#programista15k #datascience #artificialintelligence #sztucznainteligencja
Ciekawe w jaki sposób Microsoft będzie redukował koszty, do momentu rozwoju AI, które będzie generowało większe przychody. Zarabiają na innych rzeczach, więc nie jest to pewnie jakiś wielki problem, ale jeśli rentowność nie zacznie rosnąć, może się nim stać. Ciekawe czy pójdą np. w reklamy, albo transfer kosztów obliczeniowych na klienta. Nie wiem jak to ostatnie mogłoby wyglądać.
Ciekawe w jaki sposób Microsoft będzie redukował koszty, do momentu rozwoju AI, które będzie generowało większe przychody. Zarabiają na innych rzeczach, więc nie jest to pewnie jakiś wielki problem, ale jeśli rentowność nie zacznie rosnąć, może się nim stać. Ciekawe czy pójdą np. w reklamy, albo transfer kosztów obliczeniowych na klienta. Nie wiem jak to ostatnie mogłoby wyglądać.
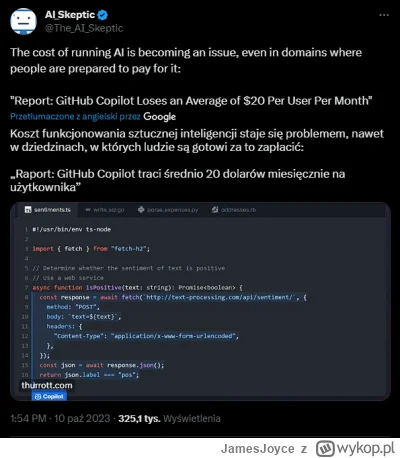
źródło: copilot
Pobierz@JamesJoyce narazie jest proces uzależnia użytkowników. Jak już nie będą mogli sobie pozwolić na dokładanie do interesu to ustala takie ceny żeby to się spinalo. Ci których nie będzie stać zrezygnują, ale do tego czasu złowią sporo osób których będzie stać.
@ZyfiDynock: od kilku lat procesory graficzne są tworzone pod AI. Problem polega na tym, że jest ich za mało i są niewystarczająco wydajne. Generalnie zgadzam się, że przyszłość przyniesie lepsze GPU, ale wciąż, będą one bardzo drogie. Zwykła 4090 kosztuje ~10k, a gdzie 4090 do poważnych zastosowań na poziomie llmów.
Ja korzystam z ChatuGPT w plusie i jestem zadowolony. Ale to dlatego, że przyjmuję na klatę jego ograniczenia i nie oczekuję
Ja korzystam z ChatuGPT w plusie i jestem zadowolony. Ale to dlatego, że przyjmuję na klatę jego ograniczenia i nie oczekuję


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Wiadomo coś nt. BloombergGPT? Jakiś czas temu było głośno o tym projekcie, jest artykuł na arxivie i Medium, ale nie mogę znaleźć modelu do pobrania/
https://medium.com/codex/bloomberggpt-the-first-large-language-model-for-finance-61cc92075075