#bigdata #informatyka #hadoop
Witam, szukam szkolenia z Administracji Hadoopa (nie z Cloudery), cena jak by nie gra roli, najlepiej jak w było to szkolenie stacjonarne w Warszawie
Ktoś był i poleca ?
Witam, szukam szkolenia z Administracji Hadoopa (nie z Cloudery), cena jak by nie gra roli, najlepiej jak w było to szkolenie stacjonarne w Warszawie
Ktoś był i poleca ?
























{kind=link}
{kind=link}
{kind=link}
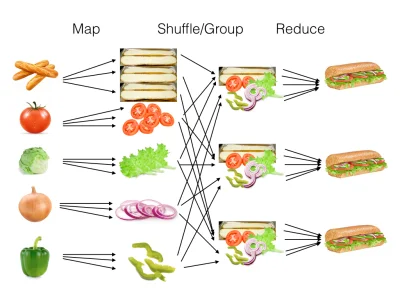
Czy ktoś z was miał okazję pracować z technologią hadoop w kontekście zadań związanych z tematyką Machine Learning ? jeśli tak to jak wyglądał proces tworzenia modeli, obróbki danych od początku rozpoczęcia ciągu technicznego ?
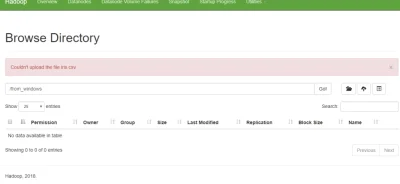
Jak rozumiem Hadoop to jest jakby to powiedzieć ogromny magazyn na przechowywanie dosłownie różnych danych z różnych systemów dane te mogą być ustrukturyzowane, nieustrukturyzowane itp. wchodzą oni to jak dobrze rozumiem przestrzeni HDFS na surowo, i