Aktywne Wpisy

kinasato +105
#ukraina #wojna #rosja #wojsko
Przepraszam, że tak głupio zapytam, ale nie śledziłem tagu.
https://twitter.com/realGon70/status/1763867557629481224?t=KY75c2yrtCyDbDxLaXfAlQ&s=19
Czy to już zostało zgłoszone do ABW?
Przepraszam, że tak głupio zapytam, ale nie śledziłem tagu.
https://twitter.com/realGon70/status/1763867557629481224?t=KY75c2yrtCyDbDxLaXfAlQ&s=19
Czy to już zostało zgłoszone do ABW?

officer_K +202
Sekta grzegorza "ruskiego grzesia" brauna przeszła od słów do czynów...
#k0nfederosja
#konfederacja #bekazkonfederacji #k0nfedepis #bekazk0nfedepisu #bekazprawakow #bekazpodludzi #ukraina #rosja #polska #wojna #sejm #neuropa #polityka
#k0nfederosja
#konfederacja #bekazkonfederacji #k0nfedepis #bekazk0nfedepisu #bekazprawakow #bekazpodludzi #ukraina #rosja #polska #wojna #sejm #neuropa #polityka
źródło: 1000008095
Pobierz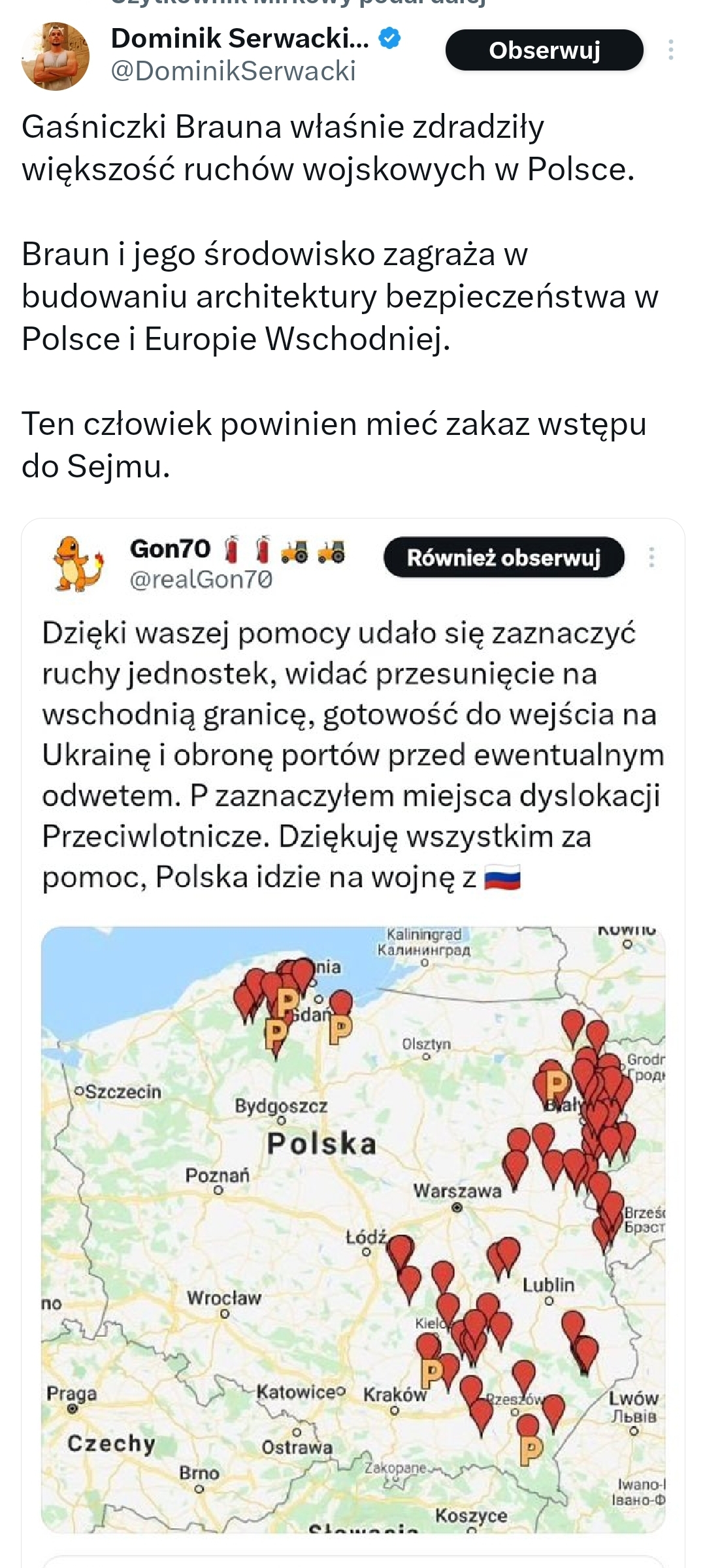{kind=link}
Aktywne Znaleziska





Niech X będzie zmienną losową o wartościach x1,...,xJ. Prawdopodobieństwo, że X=xi oznaczamy pi. Dane wynikające z obserwacji w n-elementowej próbce, powstającej z niezależnego losowania wartości cechy X możemy zapisać w tablicy kontyngencyjnej:
n1 n2 n3 ... nJ
p1 p2 p3 ... pJ
gdzie p1 +... + pJ =1
Parametr ni określa ile razy zaobserwowano w próbce wartość xi. Rozkładem związanym z tą tablicą jest rozkład zmiennej losowej Ni określającej, ile wyników cechy X na poziomie xi wystąpi w próbce (rozkład ten zależy od rozkładu zmiennej X). Dotąd jest wszystko jasne. Problem mam odtąd:
Różne sposoby uzyskania informacji w próbce mają wpływ na rozkład zmiennych Ni.
1. Rozkład dwumianowy (Bernoulliego) B(p)
Powtarzamy n-krotnie eksperyment, polegający na wykonaniu n0 niezależnych powtórzeń zmiennej o dwóch poziomach: "sukces" i "porażka", gdzie prawdopodobieństwo sukcesu wynosi p. Zmienna X mierzy liczbę sukcesów w n0 powtórzeniach, zaś ni jest liczbą eksperymentów w której wystąpiło xi sukcesów.
(Mój komentarz - z tego co rozumiem to analizujemy zmienne X1, ..., Xn, gdzie Xi ma rozkład Bernoulliego B(n,p)). Wówczas:
P(N1 = n1, N2 = n2, ... , NJ = nJ ) = iloczyn (od i=1 do J) (n_0 * x_i * p^(x_i) * (1-p)^(n0 - xi) )^(ni)
Pytanie: skąd taki wzór??? Za Chiny Ludowe nie mogę tego dostać, a już nie mam pojęcia skąd w nawiasie wzięło się n0 * xi . Czy ktoś byłby wyjść od rozkładu Bernoulliego i uzyskać ten wynik?
2. Rozkład Poissona z parametrem k. Wówczas
P(N1 = n1, ..., NJ = n_J) = iloczyn (od i=1 do J) exp(-k * n_i) * (k^ (xi) / xi ! ) ^ (ni)
Tutaj otrzymałem też inny wynik, choć nieco podobny. Według mnie w powyższym wyniku nie uwzględnia się tego, w których spośród n doświadczeń wypadł wynik x1, w których wynik x2, itd. Czyli wg mnie powyższe wyrażenie powinniśmy przemnożyć przez C(n,n1) * C(n-n1,n2) * ... * C(n-n1-...-nJ-1 , n_J)
Co robię źle lub co rozumuję źle? Z tych rozkładów autor korzysta dalej w książce, więc raczej niema możliwości, żeby gdzieś tu był błąd.
#matematyka #statystyka
Jest to rozkład IID (independant and identically distributed) więcej niż jednej próby Bernoulliego.
Dla czytelniejszego przedstawienia problemu wklejam link do forum, gdzie ten problem umieściłem
http://www.matematyka.pl/392785.htm
Intryguje mnie strasznie n0 powtórzeń.
Powtórzeń powinno być n, n0 może być numerem... zerowego (?) powtórzenia.
Wtedy miałbyś X1, ..., Xn wyników.
Czyli X1 = {0, 1}, X2 = {0, 1}, ..., xn = {0, 1}
Czy nie powinno być P(X1 = x1, ..., Xn = x_n)?
(n po k) by odpowiadało Twojemu obecnemu (n0 * xi),
p^k = obecne p^x_i
(1-p)^(n-k) = (1-p) ^ (n0-xi)
zostaje jeszcze ostatnia potęga.
Myślę, że tędy droga.
źródło: comment_HGRRzK4y6wXRw6hKgb7726JZllSxTZhm.jpg
Pobierz