
Lenalee
#muzyka #tesseract

- l00cipher
- konto usunięte
- evolved
- Hoverion
Wszystko
Wszystkie
Archiwum

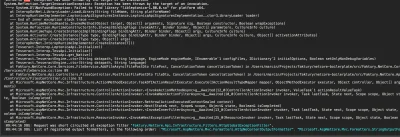
źródło: comment_1605518603Y3scO7oW6DY5tYUMVB43sd.jpg
Pobierz
szerokość obiektu jest większa od 25% szerokości całego obrazka;
wysokość obiektu jest wieksza od 33% wysokości całego obrazka;
stosunek szerokości do wysokości obiektu jest mniejszy od 0.1;
stosunek szerokości do wysokości obiektu jest
czytam sobie jak poprawić wyniki teserakta i czy może openCV nie robi roboty
no i wychodzi że openCV to obudowa do tesseracta?

źródło: comment_DkDLZbvWsW5uQGmA69Mh3wnNnWs865aQ.jpg
Pobierz

źródło: comment_QxZMUqQTVxTLafDYnRfLvk91G5cfMHhq.jpg
Pobierz


Ciekawsze rzeczy od 1:00, w powiązanych demo ze słoneczkiem
z
Nagranie ze studia na żywo zespołu, który poszerza horyzonty muzyki metalowej. Dla fanów melodyjnej i jednocześnie cięższej muzyki, warto posłuchać.
z






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
BTW. nie używaj polskich nazw w kodzie ( ͡° ͜ʖ ͡°)