Aktywne Wpisy

Yaszu +138
źródło: temp_file1600486307961802302
Pobierz
dom_perignon +135
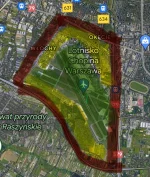
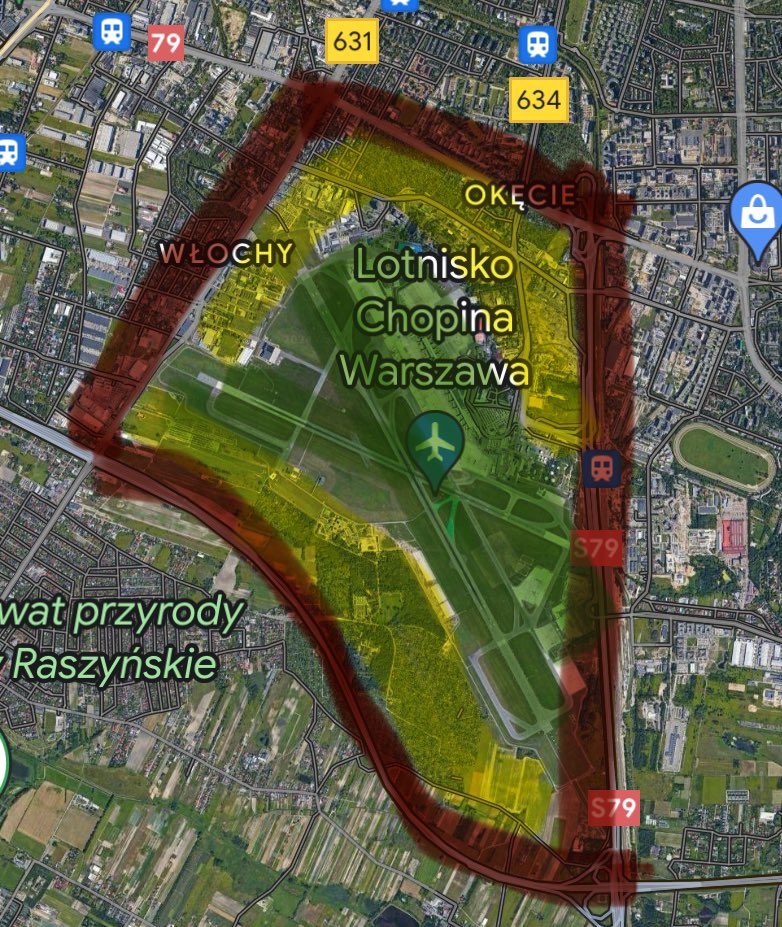
Czyli CPK uwalone. Zamiast tego ma być rozbudowa Okęcia, która jest nierealna ze względu na bariery przestrzenne.
Czyli audyty CPK to ściema, dotychczasowe analizy i wydane 3 mld zł na projekty i grunty w piach, za to wydamy 2,4 mld zł na Chopina, który i tak nie zwiększy przepustowości, bo nie ma slotów.
XD
#cpk #ekonomia #bekazlewactwa
Czyli audyty CPK to ściema, dotychczasowe analizy i wydane 3 mld zł na projekty i grunty w piach, za to wydamy 2,4 mld zł na Chopina, który i tak nie zwiększy przepustowości, bo nie ma slotów.
XD
#cpk #ekonomia #bekazlewactwa
źródło: GMWvbInXYAA8A1H
Pobierz




{kind=link}
{kind=link}
Dla wszystkich zainteresowanych data science/ai, 4 dni temu Karpathy wypuścił świetne video,
w którym pokazuje jak zbudować Tokenizer od zera.
https://youtu.be/zduSFxRajkE?si=TjRhcwFlxm2yvULH
Tokenizer to bardzo istotny element pipelinu nlp, który służy do konwertowania tekstu na sekwencję tokenów, tworzenia liczbowej reprezentacji tokenów i łączenia ich w tensory.
Prosty przykład zdania: "Wykopki to najlepsi ludzie pod słońcem"
Etap 1 (Podział na mniejsze części): "Wykopki", "to", "najlepsi", "ludzie", "pod", "słońcem"
Etap 2 (Przekształcenie na numery, tutaj fikcyjne, pochodzące z wytrenowanych wcześniej wielkich korpusów): "Wykopki" -> 12345, "to" -> 67, "najlepsi" -> 8910, "ludzie" -> 1112, "pod" -> 1314, "słońcem" -> 1516
Etap 3 (Dodanie specjalnych znaczników, pozwalają one na określenie początków i końców zdani): Początek zdania -> 101, Koniec zdania -> 102
Etap 4 (Wynik końcowy): 101, 12345, 67, 8910, 1112, 1314, 1516, 102
Podstawowy pipeline nlp, np. przy użyciu architektury Huggingface można sobie przeklikać tutaj:
https://colab.research.google.com/github/huggingface/notebooks/blob/main/transformers_doc/en/preprocessing.ipynb