Polscy naukowcy opracowali duży model językowy bardziej wydajny niż ChatGPT
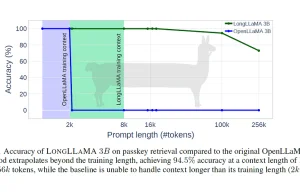
Mowa o LongLLaMa, który oparto na oprogramowaniu OpenLLaMA, stworzonym przez Meta – właściciela Facebooka. Ten duży model językowy opracowany przez naukowców z UW, PAN i IDEAS NCBR ma pozwolić obsługiwać 64 razy więcej tekstu niż ChatGPT. To zapowiada nowy krok w rozwoju modeli językowych.
- #
- #
- #
- #
- #
- #
- 107
- Odpowiedz






Komentarze (107)
najlepsze
@wieczny-student: Nie ilość a jakość się liczy. Modele o bardzo długim kontekście są zawsze realizowane nie wprost ale pewnym "trikiem". Jeżeli chciałbyś skalować "normalnie" to attention matrix będzie miało rozmiar 100k x 100k, bo to jest kwadratowa macierze od długości kontekstu. Ani się taka nie zmieści w pamięci ani nie będziesz mógł jej wytrenować.
Dlatego robi się różne uproszczenia, streszczenia,
@moj_wykopowy_login: W bardzo dużym skrócie - oblicza ważność (wpływ) każdego słowa z każdym pozostałym w kontekście. Dlatego w klasycznych transformersach musi być macierz kwadratowa bo jak masz 100 wyrazów w kontekście to musisz obliczyć wpływ każdego ze 100 wyrazów na wszystkie pozostałe.
W jaki sposób oblicza wpływ tych wyrazów na wszystkie pozostałe? Podczas trenowania "przygląda"
to nie żadna sztuczna inteligencja tylko model językowy, algorytm xd
- ChatGPT co sądzisz o tym, że Polscy naukowcy opracowali duży model językowy bardziej wydajny niż Ty masz?
- Je...ni rasiści nie mają o niczym pojęcia! xD
chat liczy, mieli, myśli
@hipolit-cacek: nic, bo i tak na tym nie zarobią
Np do dwóch zastosowań - dajmy na to taki przykład:
1) pomoc przy programowaniu bez zbędnych dodatkowych opisów - typu pisze mu funkcje jaka ma napisać (czyli co funkcja ma robić itd) i ją tworzy.