Aktywne Wpisy
Thror +1137
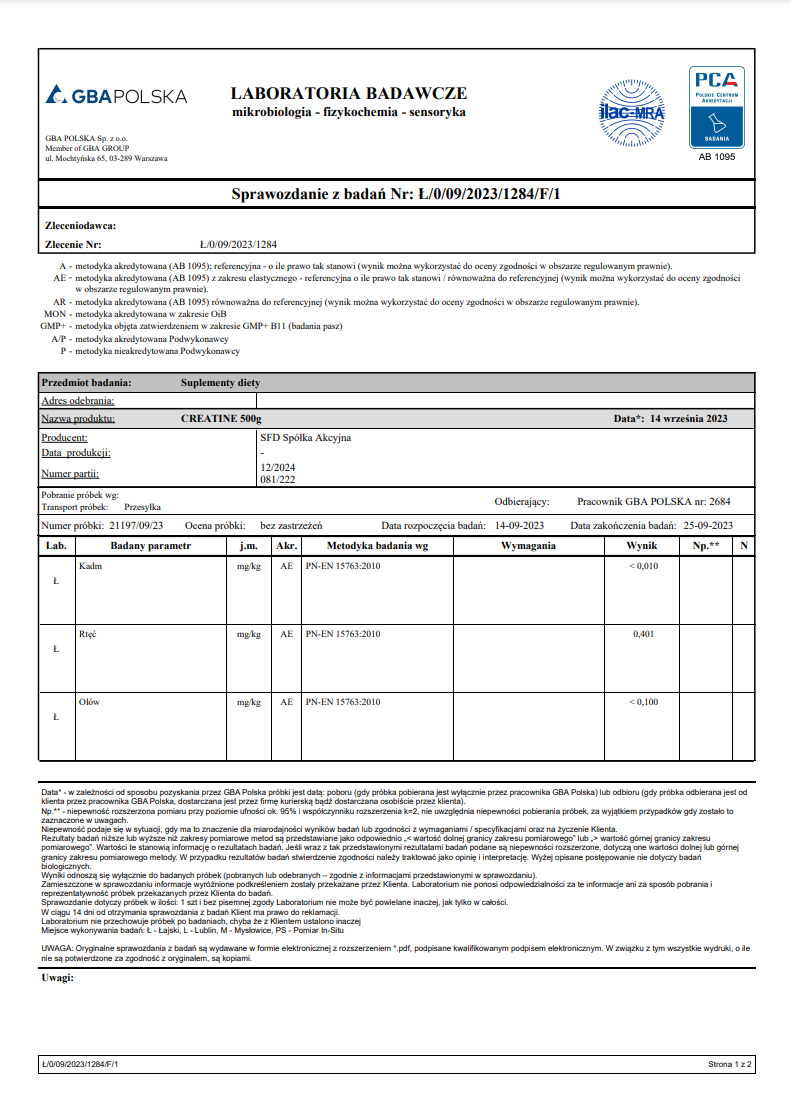
Zgodnie z obietnicą (link) przesyłam wyniki badań mojej próbki kreatyny firmy SFD (lepiej późno niż wcale).
Poziom rtęci został przekroczony czterokrotnie. Na wszelki wypadek poinformowałem sanepid w Opolu o przekroczeniu norm. Sanepid potwierdził, że moja partia została wycofana ze sprzedaży. Strona SFD także to potwierdza, po wpisaniu numeru partii 081.222
https://sklep.sfd.pl/produkt/SzukajPartii.aspx
#sfd #kreatyna
Poziom rtęci został przekroczony czterokrotnie. Na wszelki wypadek poinformowałem sanepid w Opolu o przekroczeniu norm. Sanepid potwierdził, że moja partia została wycofana ze sprzedaży. Strona SFD także to potwierdza, po wpisaniu numeru partii 081.222
https://sklep.sfd.pl/produkt/SzukajPartii.aspx
#sfd #kreatyna
{kind=link}


nad__czlowiek +38
#programowanie #programista15k #pracait #korposwiat #pracbaza
Śmieszna jak logika programistów na udawanej działalności gospodarczej w celu oszukiwaniu na podatkach (ładnie jest to nazwane optymalizacją podatkową). Nikt się oczywiście nie czepia gości co mają kilku klientów jednocześnie, dodatkowe fuchy albo nawet mają od lat jednego klienta i wystawiają grzecznie jedną fakturę co miesiąc - ważny jest wtedy tylko i wyłącznie fakt czy to B2B różni się zdecydowanie od UoP, bo w większości przypadków posadź
Śmieszna jak logika programistów na udawanej działalności gospodarczej w celu oszukiwaniu na podatkach (ładnie jest to nazwane optymalizacją podatkową). Nikt się oczywiście nie czepia gości co mają kilku klientów jednocześnie, dodatkowe fuchy albo nawet mają od lat jednego klienta i wystawiają grzecznie jedną fakturę co miesiąc - ważny jest wtedy tylko i wyłącznie fakt czy to B2B różni się zdecydowanie od UoP, bo w większości przypadków posadź
Aktywne Znaleziska





vs
https://www.techpowerup.com/gpu-specs/radeon-hd-7950.c307
Jedna karta kosztuje 50-80zł a druga 150-300zł, lecz oba są tak samo efektowne w #machinelearning przy użyciu OpenCLa.
Tylko czy da się pamięć ram z płyty przydzielić do tych obliczeń na GPU w OpenCLu?
W końcu zawsze mam wolne 40gb ddr2 w zapasie ( ͡° ͜ʖ ͡°)
https://timdettmers.com/2018/12/16/deep-learning-hardware-guide/
Jeśli chodzi o trening sieci neuronowych to musisz cały model zmieścić na pamięć karty, RAMu trzeba mieć tyle żeby swobodnie przetwarzać dane przy użyciu procesora, czyli niemniej niż masz pamięci na karcie + jakiś zapas.
Pamiętaj że na GPU nie musisz mieć całej bazy danych, tylko cały model + miejsce na przeprowadzenie propagacji dla rozsądnej wielkości mini
@Poziokat: @majsterV2: Tego też w sumie nie trzeba, bo np. pytorch ma utils.checkpoint i wtedy backprop jest robiony jakby osobno. Wychodzi drożej obliczeniowo, ale wymaga trzymania gradientu tylko dla jednej warstwy na raz.