Aktywne Wpisy
mrukamani +36
źródło: jkghkjgkgkjg
Pobierz{kind=link}

WielkiNos +167
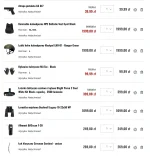
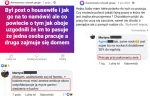
Według lewaczek każdy ma prawo żyć jak chce jeśli nie robi przy tym innym krzywdy. No chyba że chodzi o tradycyjny podział ról. Wtedy trzeba skrytykować kobietę i uswiadomić ją jak nisko upadła. Tu mamy przykład jednej z takich wypowiedzi
Okazuje się, że wyjmowanie plastrów sera z opakowania dla męża i dzieci żeby zrobić kanapki to brak ambicji, ale wkładanie sera do opakowania na taśmie produkcyjnej już jest wystarczająco ambitne.
#lewackalogika #
Okazuje się, że wyjmowanie plastrów sera z opakowania dla męża i dzieci żeby zrobić kanapki to brak ambicji, ale wkładanie sera do opakowania na taśmie produkcyjnej już jest wystarczająco ambitne.
#lewackalogika #
źródło: temp_file4686480767003391737
Pobierz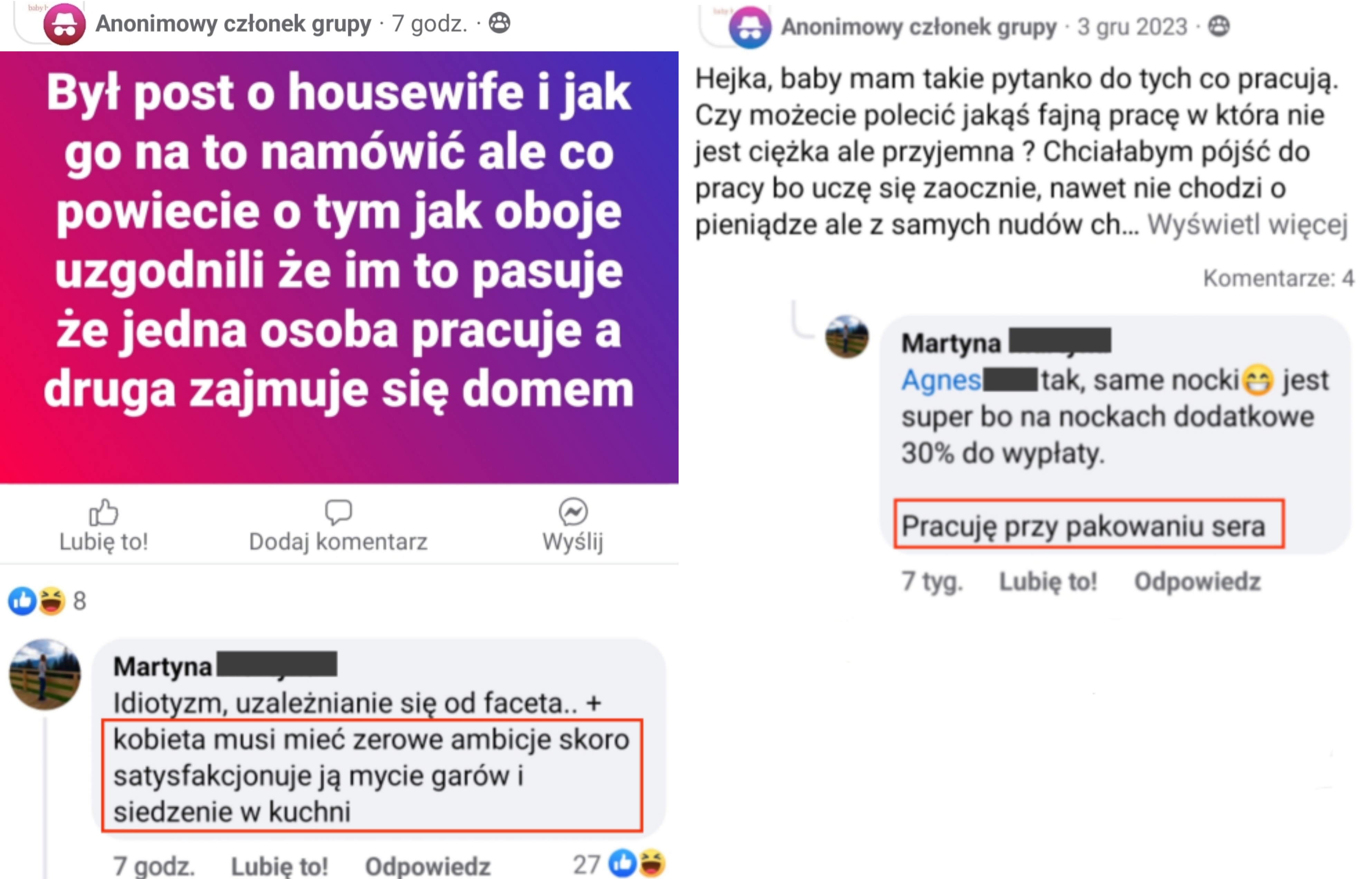{kind=link}
Aktywne Znaleziska





Mamy dużą bazę danych (Oracle), z której generujemy raporty (SQL-ki z różnymi count, group by, join, where itd).
Obecnie mamy w bazie tyle danych, że takie zapytania wykonują się długo (mimo pozakładanych indeksów i optymalizacji przez speca od DB).
Chcielibyśmy użyć czegoś, żeby obok "indeksować" potrzebne dane do raportów (nie wiem, jakaś inna "baza").
Przy okazji, żeby łatwiej tworzyć nowe raporty (np. coś w stylu jak są hurtownie danych i kostki OLAP/ETL).
Czego do tego najlepiej użyć? Miałem dwa pomysły, ale chyba żaden nie jest dobry:
- Elasticsearch: Łatwo indeksować i wyszukiwać. Jest to "baza danych", więc mam gotowe rozwiązanie gdzie mogę obok przechowywać dane (ten "index"). Ale problematyczne są group by (których mamy sporo) i raporty agregujące dane (tzn. ciężko osiągnąć coś w stylu kostek OLAP).
- Spark: Wydaje mi się, że łatwo osiągnąć te group by i agregacje. Ale co z przechowywaniem tych zagregowanych danych? Nie chciałbym za każdym razem ciągnąć wszystkiego z bazy i liczyć od nowa. A tak w tutorialch jest: pociągnij wszystko z bazy, przelicz, zapisz do CSV i koniec. A jak jutro chcesz nowy raport z aktualnymi danymi, to od nowa wszystko (i mielisz bazę na produkcji :/ ). Trzeba sobie samemu podpiąć bazę i ręcznie zapisywać, a potem wczytywać? Czy inaczej się do tego podchodzi? Może coś w HDFS?
W którym kierunku powinienem iść? (Uwzględniając też dla mnie przydatność na rynku pracy.) A może coś innego? Słyszałem o rozwiązaniach np. QlikView lub Microsoft SQL Server, gdzie jest już gotowiec ze wszystkim (nawet z GUI, że można sobie takie raporty wyklikać). Ale kosztuje to miliony monet i jako Java dev wolałbym coś czego się używa na rynku (np. Spark często się pojawia w wymaganiach o pracę - chociaż słyszałem też głosy, że się od tego odchodzi), a nie zostać konfiguratorem jakiegoś płatnego rozwiązania.
Komentarz usunięty przez autora
Ew możesz odwzorowac relacyjna bazę w hivie ale to dość złożony proces.
Sparka mozesz wpiac do powerbi lub tableau. Impale tez.
Jak cos to chętnie pomogę.
Komentarz usunięty przez autora
Po drugie, Spark jest imho najlepszym rozwiazaniem do tego. I nie musisz wszystkiego obliczac za kazdym razem raczej, nie pamietam juz szczegolow ale pogoogluj koncpet Sparkowego "checkpoint" - on jest w
@MikelThief: @Myzreal: myślałem o tym na początku, żeby po prostu zrobić replikację do drugiej bazy Oracle obok. Aktualnie tego nie mamy, bo raporty, które są konieczne jeszcze obecnie dają radę się wykonywać (ale nie potrwa to długo). Jak mamy przerzucać dane obok, to zamiast takiej samej bazy wolelibyśmy coś dedykowanego pod to
Nastepnie procesowac np za pomoca nifi dalej.
Co do sqoopa mozesz ustawic crona lub oozie(przy hdfs) . W komendzie sqoopa mozesz podac warunek where (on dziala w calosci po jdbc)
Spark ma opcje podlaczenia sie za pomoca jdbc do bazy danych i
https://sqoop.apache.org/docs/1.4.2/SqoopUserGuide.html#_incremental_imports
w sqoop pobierasz całą tabele --table albo zapytaniem w --query mozesz sobie wybrac co tam chcesz, no i jak nawet byś pobierał całą tabele to sqooop moze to szybko robić (zwiekszenie num-mappers i podanie kolumny --split-by)
Cykliczne agregacje danych mają sens wtedy, gdy dane wejściowe albo wyjściowe będą się do tego nadawały.
Weźmy przykład z Mirko. Zakładając że masz tabele userów, wpisów i plusów, która zawiera id wpisu i id usera, robisz zapytanie do plusów o X wpisów z największą ich liczbą. Utrwalasz wtedy np. datę wygenerowania danej, id wpisu, liczbę plusów. Taka dzienna
Spark to nie jest jakieś magiczne narzędzie, które potrafi samo coś mądrego policzyć. Siłą Sparka jest to, że potrafi rozdystrybuować zadania na X nodów, całkiem dynamicznie i szybko. No ale po co ten Spark? Tutaj, moim zdaniem kluczowe są:
- zdolność obsługi dużej ilości danych, bez struktury. Tu właśnie wchodzi hdfs (i różne jego odpowiedniki jak s3, gs). Wyobraź sobie, że masz logi aplikacji w