Aktywne Wpisy

S_T_A_L_K_E_R_ +275
{kind=link}

elo_kebab +6
Jak się czujecie z tym, że u nas w 99% robi się OUTSOURCING I CRUDY. Nie masz szans na ciekawe wyzwania inzynieryjne. U nas nie ma R&D w programowaniu. Musisz celować w jakieś AI/ML stanowiska albo cybersecurity, całkowicie inna działka niż: web-dev, dev, devOps, testy, cloud architect itd.
W devie ciągle tylko klepanie - @RestController, @autowired, @Trasanctional, RESTy, CRUDy, Kafki, Redisy, Elasticsearche. S3 i Lambdy. Kubernetesy. Robota
W devie ciągle tylko klepanie - @RestController, @autowired, @Trasanctional, RESTy, CRUDy, Kafki, Redisy, Elasticsearche. S3 i Lambdy. Kubernetesy. Robota
Aktywne Znaleziska




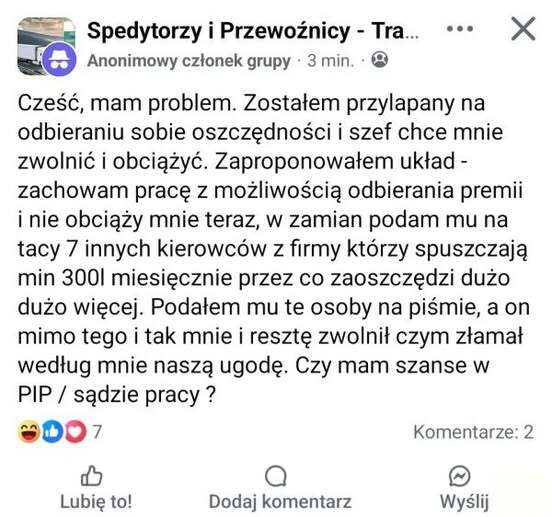
Ale wtedy pisowskie trollw podbiłyby twittera do końca...
Google Translate ma pod spodem model w 'sztucznym' języku, a badania nad word2vec'iem wykazały, że dane słowa oraz ich tłumaczenia, jeśli wyuczysz model na korpusach różnych języków, będą blisko siebie w wygenerowanej przestrzeni.
Nie wiem do czego tego potrzebujesz; ale możliwe jest że albo to przyszłe API albo nawet AI Dungeon by wystarczyło? AI Dungeon to teoretycznie "gra" ale w praktyce można wrzucić dowolnego prompta (jak tutaj); tyle że
Chociaż w sumie zasada jest raczej inna niż opisałeś w tym przypadku; GPT ma przewidywać kolejne tokeny na podstawie kontekstu ("poprzedniego" tekstu). Więc
Word2Vec zwraca wektory per słowo. Przestrzeń, w której znajdują się wektory, generowana jest na podstawie powiązań między słowami w tekście. I teraz w zależności od podejścia (główne to są skipgram i cbow, w skrócie przewidywanie słowa na podstawie otoczenia lub przewidywanie otoczenia na podstawie słowa) uczy się w różny sposób. Cechą takich wektorów jest to,
Tak, wg. sposobu działania który opisujesz rzeczywiście "łatwiej" o niezależność od języka.
PS: nie spodziewałem się
@Sinity: piękne :D