Aktywne Wpisy

#programista15k #programista25k #pracait #zarobki #it
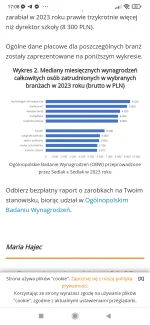
Panowie programiści, nie jestem z branży, ale jest mi ktoś w stanie wytłumaczyć dlaczego na wykopie każdy jest programista 25k na fakturze, a raport z wynagodzenia.pl pokazuje to
https://wynagrodzenia.pl/artykul/podsumowanie-ogolnopolskiego-badania-wynagrodzen-obw-w-2023-roku
Panowie programiści, nie jestem z branży, ale jest mi ktoś w stanie wytłumaczyć dlaczego na wykopie każdy jest programista 25k na fakturze, a raport z wynagodzenia.pl pokazuje to
https://wynagrodzenia.pl/artykul/podsumowanie-ogolnopolskiego-badania-wynagrodzen-obw-w-2023-roku
źródło: Screenshot_2024-04-16-17-08-41-050_com.android.chrome
Pobierz{kind=link}

Lekarz_7k +53
Lekarz internista nie jest do niczego potrzebny w dzisiejszych czasach. Czuje się jak kompletny idiota gdy mówie pacjentowi to co on może wygooglowac w 10 sekund i wiem, że to wygooglował. Jeszcze gorzej się czuje, gdy musze mu wypisać recepte na lek, który on sam wie że musi brać bo również wyczytał to w googlu i bardzo często poprawnie wytypował dla siebie lek. Wszystko jest w internecie. Pacjenci mnie nie szanują, i

źródło: IMG_8777
Pobierz{kind=link}
Aktywne Znaleziska




Z wstepnego rozeznania mysle zeby sprobowac #tensorflow i #opencv . Ktoś próbował czegos takiego i moze polecic inne rozwiazania? Moze jest cos prawie gotowego opensourcowego co moznaby rozwinąć?
#programowanie #programista15k
@WilczurZnahor: Powodzenia ( ͡° ͜ʖ ͡°)
źródło: comment_1636316728VGzuFqGr2Bw8lXgxyp2CAk.jpg
Pobierz@WilczurZnahor: A to jeszcze wtedy musiałbyś wziąć pod uwagę przedrewolucyjną ortografię, co dość dużo zmienia (zniknięcie liter і, ѳ, ѣ oraz w dużej mierze ъ bardzo zmienia kształt rosyjskiego tekstu) A co do genealogii i języka niemieckiego, to dodam, że dominujący 100 lat temu był Kurrentschrift, który zupełnie nie przypomina ani współczesnego pisma odręcznego, ani ówczesnego pisma odręcznego używanego przez Polaków: [↓]
źródło: comment_1636318022cv7h4FbjMDusTqEpO88nVP.jpg
Pobierz@WilczurZnahor: Ciężko powiedzieć, ale raczej tak. Występujące w końcówkach wielu nazwisk i przymiotników ій może być błędnie zinterpretowane jako ш lub т; ъ na końcu wyrazu jako ь, ч, г lub б; ѳ jako э, е lub о; ѣ to już w ogóle pole do popisu dla modelu do zgadywania. Biorąc pod uwagę, że interesują
źródło: comment_1636324641kJbauGFXm2yXNqsuTfpLsR.jpg
Pobierz